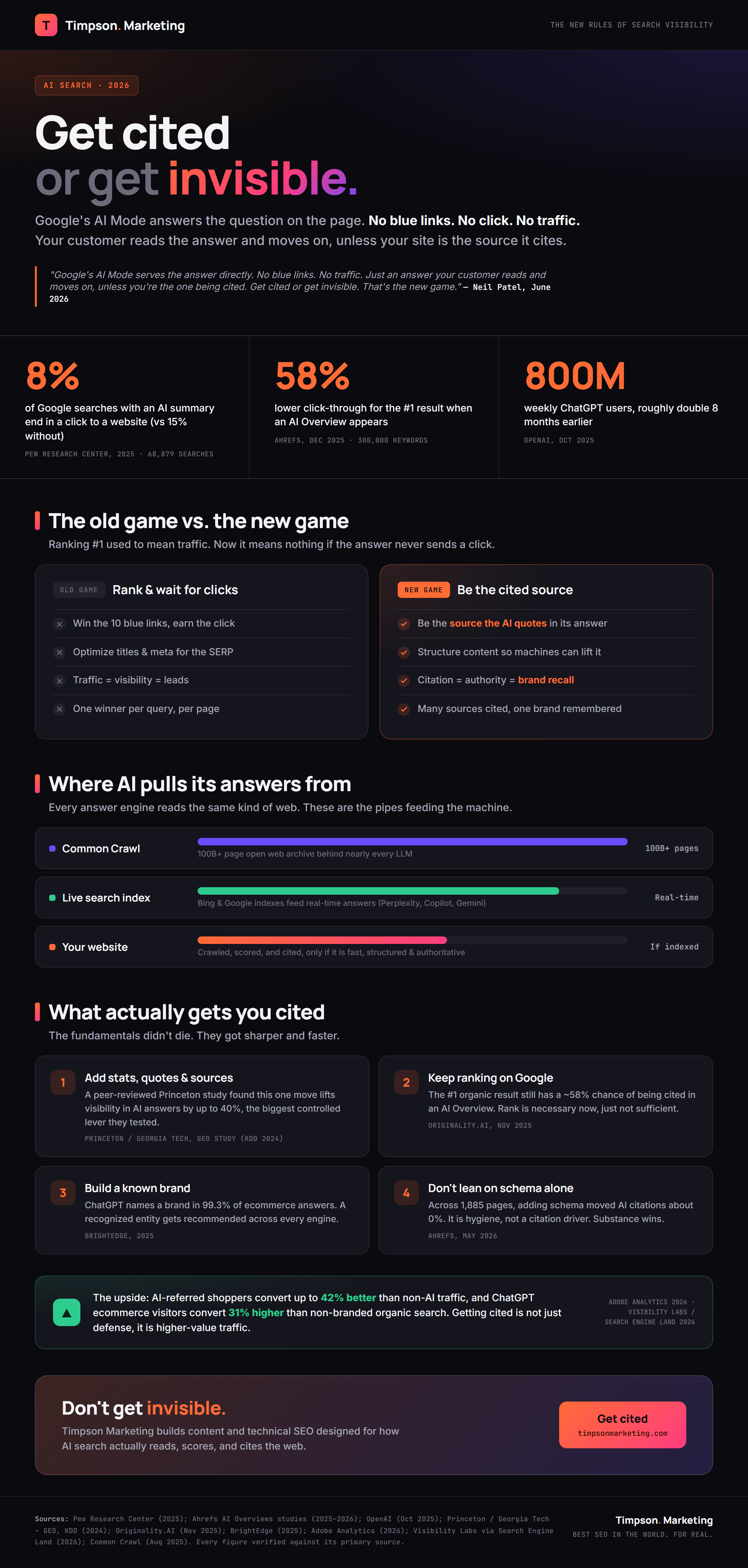
100B+
Web pages in the Common Crawl archive that feed nearly every LLM.
Common Crawl, Aug 2025
ChatGPT, Claude, Gemini, Perplexity, Copilot. Every major AI tool has a different data diet, and the mix decides what it says about your industry, your competitors, and you. Here is exactly where each one reads before it answers.
Nearly every major AI model is built on the same foundation: Common Crawl, a nonprofit archive of 100+ billion web pages. On top of that, each platform layers its own mix of books, code, licensed data, and (for tools like Perplexity, Gemini, and Copilot) live web search. The practical takeaway for businesses: if your site is fast, structured, and authoritative, it feeds these systems. If it is thin or blocked, you are invisible to them.
A large language model learns by processing enormous text datasets during a phase called pre-training. It reads billions of documents, learns the statistical patterns between words, and builds an internal map of how language works. After that, the team fine-tunes the model on curated examples to make it more helpful, accurate, and safe.
The critical implication: the model cannot know what it never read. It cannot be more reliable than its sources allow, and it inherits the biases, gaps, and errors in those sources. Training data is not a technical footnote. It is the foundation of everything the model says, including what it says about your company.
Common Crawl is a nonprofit that has crawled and archived the public web since 2008. As of its August 2025 archive, it holds over 100 billion web pages, adding roughly 2.44 billion pages (424 TiB) every month across 47.5 million hosts. ChatGPT, Claude, Gemini, LLaMA, and most other major models all draw from it.
What is inside Common Crawl? Personal blogs, forum threads, news articles, product pages, Reddit discussions, academic papers, Wikipedia. Basically the whole public internet, filtered and deduplicated, going back nearly 20 years. If your website has been publicly indexed, it has almost certainly been crawled, and it may already shape how AI describes your industry.
The raw ingredients overlap, but the recipe differs. Here is the data diet, real-time capability, and knowledge cutoff for each major platform.
Trained on roughly 13 trillion tokens: mostly Common Crawl web text, plus WebText2 (links upvoted on Reddit, weighted about 5x heavier than raw web), books, and code. That Reddit weighting skews the model toward English, US-based, tech-literate perspectives, a bias baked in at the data layer. Base ChatGPT does not browse; the Search feature adds live results via Bing.
Anthropic is the most opaque about its exact corpus, but the differentiator is the alignment layer, not the raw data. Claude is trained with Constitutional AI: a written set of principles (drawn from the UN Declaration of Human Rights, Apple's terms of service, and Anthropic's own testing) that the model uses to generate synthetic training examples. The January 2026 revision expanded this to an 80-page framework, open-sourced under Creative Commons.
Gemini trains on Common Crawl plus datasets like The Pile (825GB across 22 sources, including 196,640 books), YouTube transcripts, and Google's own search index. A 2024 legal filing revealed Google removed 80 billion of 160 billion tokens after publisher opt-outs. No competitor owns both the world's largest search index and a frontier model, which is why Gemini's live Search integration is so strong.
Perplexity is not a traditional model. It is an answer engine built on Retrieval-Augmented Generation: it reads your intent, fires a live search (primarily the Bing index), summarizes the retrieved pages, and cites every claim with a numbered source. It does not answer from memory. It answers from the live web, which is why its information is current to the hour.
Copilot runs on OpenAI's models (Microsoft owns roughly 49% of OpenAI) plus Bing's live web index. The same Bing crawl feeds Copilot, ChatGPT's Search feature, DuckDuckGo, and Ecosia. One note for businesses evaluating it internally: content processed by Microsoft 365 Copilot is not used for model training.
LLaMA is not a consumer product, but it powers hundreds of downstream tools, and its training data (reproduced as the open RedPajama dataset) is the most transparent in the industry: Common Crawl (878B tokens), C4 (175B), GitHub (59B), arXiv (28B), books (26B), Wikipedia (24B), and StackExchange (20B).
| Platform | Primary source | Real-time? | Cutoff |
|---|---|---|---|
| ChatGPT (GPT-4o) | CommonCrawl, WebText2, Books | Add-on (Bing) | Oct 2023 |
| Claude | Web, Books, Constitutional AI | No | Jan 2026 |
| Gemini | CommonCrawl, The Pile, YouTube | Yes | Jan 2025 / live |
| Perplexity | Bing index (RAG, live) | Always | Real-time |
| Microsoft Copilot | OpenAI models + Bing | Yes | Model-dependent |
| Meta LLaMA | CommonCrawl, C4, Wikipedia | No | Varies |
The labs do not disclose their training-data mix. But we can measure the next best thing: which domains each engine actually pulls into its answers. Profound analyzed 680 million real citations (August 2024 to June 2025). Below is the share each domain holds within each engine's top-10 most-cited sources, plus a March 2026 ranking from Peec AI (30 million sources).

| Domain | Share of top-10 citations |
|---|---|
| Wikipedia | 47.9% |
| 11.3% | |
| Forbes | 6.8% |
| G2 | 6.7% |
| TechRadar | 5.5% |
| NerdWallet | 5.1% |
| Business Insider | 4.9% |
| NY Post | 4.4% |
| Toxigon | 4.1% |
| Reuters | 3.4% |
| Domain | Share of top-10 citations |
|---|---|
| 21.0% | |
| YouTube | 18.8% |
| Quora | 14.3% |
| 13.0% | |
| Gartner | 7.1% |
| NerdWallet | 5.9% |
| Forbes | 5.7% |
| Wikipedia | 5.7% |
| Business Insider | 4.5% |
| Medium | 3.9% |
| Domain | Share of top-10 citations |
|---|---|
| 46.7% | |
| YouTube | 13.9% |
| Gartner | 7.0% |
| Yelp | 5.8% |
| 5.3% | |
| Forbes | 5.0% |
| NerdWallet | 4.5% |
| TripAdvisor | 4.1% |
| G2 | 4.0% |
| PCMag | 3.7% |
Gemini and Google AI Mode (March 2026, Peec AI, 30 million sources): the per-domain share is not published, but the ranked order is. Gemini cites, in order: Reddit, YouTube, Wikipedia, Medium, Forbes. Google AI Mode: YouTube, Reddit, Facebook, LinkedIn, Yelp. Across all five engines in 2026, Reddit and YouTube appear in every single one.
These percentages are where each engine pulls its answers from (its citations), not its training-data mix. The exact training composition of GPT-5, Claude, and Gemini is undisclosed. Shares are measured within each engine's top-10 cited domains and shift over time, so treat them as direction, not gospel.
The tools shaping how your customers find answers were built on the same web crawls and forums that shaped the pre-AI internet. That changes the game in five concrete ways, and the data backs each one.
The businesses that win in AI search are the ones whose content is so thorough, well-sourced, and clearly structured that crawlers, retrieval systems, and training pipelines all treat it as a reliable source. That is what good SEO always was. The audience just got smarter.
No. OpenAI confirmed that conversations with ChatGPT are not used to retrain the model in real time. You would need to opt in explicitly for your data to be used in future training, and enterprise accounts have this disabled by default.
It depends on the model. Some datasets like The Pile have formal takedown processes. Google respects robots.txt for Googlebot but does not necessarily honor all opt-out signals for Gemini training data. OpenAI offers a form for training data opt-out requests, though efficacy is contested.
Perplexity is the most current for real-time factual queries. It retrieves live web results for every answer and cites them. Gemini 2.5 with AI Mode and Copilot with Bing are close seconds. Base ChatGPT without Search is frozen at its training cutoff.
Three common causes: your training data was inaccurate or outdated, the AI conflated your business with a similarly named competitor, or the model hallucinated, generating plausible-sounding but false information. Structured data, consistent NAP across directories, and authoritative content all reduce the error rate.
Full retraining is expensive and infrequent, typically once every several months to a year for a model like GPT or Claude. Real-time retrieval layers like Bing and Google Search update continuously. The gap between those two layers is where most AI errors about current events occur.
Only if the tool uses RAG or live search like Perplexity, Gemini AI Mode, or Copilot. Base models like GPT-4o do not read your website at query time. They work from what was captured in training data months or years ago.

Founder of Timpson Marketing, a boutique SEO and AI search agency based in St. George, Utah. 15 years of search optimization experience, helping local and regional businesses win visibility in Google and the AI tools now rewriting how people search. Among the earliest practitioners building GEO and LLM-optimization workflows before the discipline had an established name.